Russell Coker: DNS, Lots of IPs, and Postal
I decided to start work on repeating the tests for my 2006 OSDC paper on Benchmarking Mail Relays [1] and discover how the last 15 years of hardware developments have changed things. There have been software changes in that time too, but nothing that compares with going from single core 32bit systems with less than 1G of RAM and 60G IDE disks to multi-core 64bit systems with 128G of RAM and SSDs. As an aside the hardware I used in 2006 wasn t cutting edge and the hardware I m using now isn t either. In both cases it s systems I bought second hand for under $1000. Pedants can think of this as comparing 2004 and 2018 hardware.
BIND
I decided to make some changes to reflect the increased hardware capacity and use 2560 domains and IP addresses, which gave the following errors as well as a startup time of a minute on a system with two E5-2620 CPUs.
May 2 16:38:37 server named[7372]: listening on IPv4 interface lo, 127.0.0.1#53 May 2 16:38:37 server named[7372]: listening on IPv4 interface eno4, 10.0.2.45#53 May 2 16:38:37 server named[7372]: listening on IPv4 interface eno4, 10.0.40.1#53 May 2 16:38:37 server named[7372]: listening on IPv4 interface eno4, 10.0.40.2#53 May 2 16:38:37 server named[7372]: listening on IPv4 interface eno4, 10.0.40.3#53 [...] May 2 16:39:33 server named[7372]: listening on IPv4 interface eno4, 10.0.47.0#53 May 2 16:39:33 server named[7372]: listening on IPv4 interface eno4, 10.0.48.0#53 May 2 16:39:33 server named[7372]: listening on IPv4 interface eno4, 10.0.49.0#53 May 2 16:39:33 server named[7372]: listening on IPv6 interface lo, ::1#53 [...] May 2 16:39:36 server named[7372]: zone localhost/IN: loaded serial 2 May 2 16:39:36 server named[7372]: all zones loaded May 2 16:39:36 server named[7372]: running May 2 16:39:36 server named[7372]: socket: file descriptor exceeds limit (123273/21000) May 2 16:39:36 server named[7372]: managed-keys-zone: Unable to fetch DNSKEY set '.': not enough free resources May 2 16:39:36 server named[7372]: socket: file descriptor exceeds limit (123273/21000)The first thing I noticed is that a default configuration of BIND with 2560 local IPs (when just running in the default recursive mode) takes a minute to start and needed to open over 100,000 file handles. BIND also had some errors in that configuration which led to it not accepting shutdown requests. I filed Debian bug report #987927 [2] about this. One way of dealing with the errors in this situation on Debian is to edit /etc/default/named and put in the following line to allow BIND to access to many file handles:
OPTIONS="-u bind -S 150000"But the best thing to do for BIND when there are many IP addresses that aren t going to be used for DNS service is to put a directive like the following in the BIND configuration to specify the IP address or addresses that are used for the DNS service:
listen-on 10.0.2.45; ;I have just added the listen-on and listen-on-v6 directives to one of my servers with about a dozen IP addresses. While 2560 IP addresses is an unusual corner case it s not uncommon to have dozens of addresses on one system. dig When doing tests of Postfix for relaying mail I noticed that mail was being deferred with DNS problems (error was Host or domain name not found. Name service error for name=a838.example.com type=MX: Host not found, try again . I tested the DNS lookups with dig which failed with errors like the following:
dig -t mx a704.example.com socket.c:1740: internal_send: 10.0.2.45#53: Invalid argument socket.c:1740: internal_send: 10.0.2.45#53: Invalid argument socket.c:1740: internal_send: 10.0.2.45#53: Invalid argument ; <> DiG 9.16.13-Debian <> -t mx a704.example.com ;; global options: +cmd ;; connection timed out; no servers could be reachedHere is a sample of the strace output from tracing dig:bind(20, sa_family=AF_INET, sin_port=htons(0), sin_addr=inet_addr("0.0.0.0") , 16) = 0 recvmsg(20, msg_namelen=128 , 0) = -1 EAGAIN (Resource temporarily unavailable) write(4, "\24\0\0\0\375\377\377\377", 8) = 8 sendmsg(20, msg_name= sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.0.2.45") , msg_ namelen=16, msg_iov=[ iov_base="86\1 \0\1\0\0\0\0\0\1\4a704\7example\3com\0\0\17\0\1\0\0)\20\0\0\0\0 \0\0\f\0\n\0\10's\367\265\16bx\354", iov_len=57 ], msg_iovlen=1, msg_controllen=0, msg_flags=0 , 0) = -1 EINVAL (Invalid argument) write(2, "socket.c:1740: ", 15) = 15 write(2, "internal_send: 10.0.2.45#53: Invalid argument", 45) = 45 write(2, "\n", 1) = 1 futex(0x7f5a80696084, FUTEX_WAIT_PRIVATE, 0, NULL) = 0 futex(0x7f5a80696010, FUTEX_WAKE_PRIVATE, 1) = 0 futex(0x7f5a8069809c, FUTEX_WAKE_PRIVATE, 1) = 1 futex(0x7f5a80698020, FUTEX_WAKE_PRIVATE, 1) = 1 sendmsg(20, msg_name= sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.0.2.45") , msg_namelen=16, msg_iov=[ iov_base="86\1 \0\1\0\0\0\0\0\1\4a704\7example\3com\0\0\17\0\1\0\0)\20\0\0\0\0\0\0\f\0\n\0\10's\367\265\16bx\354", iov_len=57 ], msg_iovlen=1, msg_controllen=0, msg_flags=0 , 0) = -1 EINVAL (Invalid argument) write(2, "socket.c:1740: ", 15) = 15 write(2, "internal_send: 10.0.2.45#53: Invalid argument", 45) = 45 write(2, "\n", 1)Ubuntu bug #1702726 claims that an insufficient ARP cache was the cause of dig problems [3]. At the time I encountered the dig problems I was seeing lots of kernel error messages neighbour: arp_cache: neighbor table overflow which I solved by putting the following in /etc/sysctl.d/mine.conf:net.ipv4.neigh.default.gc_thresh3 = 4096 net.ipv4.neigh.default.gc_thresh2 = 2048 net.ipv4.neigh.default.gc_thresh1 = 1024Making that change (and having rebooted because I didn t need to run the server overnight) didn t entirely solve the problems. I have seen some DNS errors from Postfix since then but they are less common than before. When they happened I didn t have that error from dig. At this stage I m not certain that the ARP change fixed the dig problem although it seems likely (it s always difficult to be certain that you have solved a race condition instead of made it less common or just accidentally changed something else to conceal it). But it is clearly a good thing to have a large enough ARP cache so the above change is probably the right thing for most people (with the possibility of changing the numbers according to the required scale). Also people having that dig error should probably check their kernel message log, if the ARP cache isn t the cause then some other kernel networking issue might be related. Preliminary Results With Postfix I m seeing around 24,000 messages relayed per minute with more than 60% CPU time idle. I m not sure exactly how to count idle time when there are 12 CPU cores and 24 hyper-threads as having only 1 process scheduled for each pair of hyperthreads on a core is very different to having half the CPU cores unused. I ran my script to disable hyper-threads by telling the Linux kernel to disable each processor core that has the same core ID as another, it was buggy and disabled the second CPU altogether (better than finding this out on a production server). Going from 24 hyper-threads of 2 CPUs to 6 non-HT cores of a single CPU didn t change the thoughput and the idle time went to about 30%, so I have possibly halved the CPU capacity for these tasks by disabling all hyper-threads and one entire CPU which is surprising given that I theoretically reduced the CPU power by 75%. I think my focus now has to be on hyper-threading optimisation. Since 2006 the performance has gone from ~20 messages per minute on relatively commodity hardware to 24,000 messages per minute on server equipment that is uncommon for home use but which is also within range of home desktop PCs. I think that a typical desktop PC with a similar speed CPU, 32G of RAM and SSD storage would give the same performance. Moore s Law (that transistor count doubles approximately every 2 years) is often misquoted as having performance double every 2 years. In this case more than 1024* the performance over 15 years means the performance doubling every 18 months. Probably most of that is due to SATA SSDs massively outperforming IDE hard drives but it s still impressive. Notes I ve been using example.com for test purposes for a long time, but RFC2606 specifies .test, .example, and .invalid as reserved top level domains for such things. On the next iteration I ll change my scripts to use .test. My current test setup has a KVM virtual machine running my bhm program to receive mail which is taking between 20% and 50% of a CPU core in my tests so far. While that is happening the kvm process is reported as taking between 60% and 200% of a CPU core, so kvm takes as much as 4* the CPU of the guest due to the virtual networking overhead even though I m using the virtio-net-pci driver (the most efficient form of KVM networking for emulating a regular ethernet card). I ve also seen this in production with a virtual machine running a ToR relay node. I ve fixed a bug where Postal would try to send the SMTP quit command after encountering a TCP error which would cause an infinite loop and SEGV.
 I wrote previously about my
I wrote previously about my  They also provided a set of feet allowing for vertical mounting of the device, which was a nice touch.
The USB/SATA bridge chip in use has changed; the original was:
They also provided a set of feet allowing for vertical mounting of the device, which was a nice touch.
The USB/SATA bridge chip in use has changed; the original was:
 Every year since 2005 there is a very good, big and interesting Latin
American gathering of free-software-minded people. Of course, Latin
America is a big, big, big place, and it s not like we are the most
economically buoyant region to meet in something equiparable to
FOSDEM.
What we have is a distributed free software conference originally,
a distributed Linux install-fest (which I never liked, I am against
install-fests), but gradually it morphed into a proper conference:
Festival Latinoamericano de Instalaci n de Software Libre (Latin
American Free Software Installation Festival)
Every year since 2005 there is a very good, big and interesting Latin
American gathering of free-software-minded people. Of course, Latin
America is a big, big, big place, and it s not like we are the most
economically buoyant region to meet in something equiparable to
FOSDEM.
What we have is a distributed free software conference originally,
a distributed Linux install-fest (which I never liked, I am against
install-fests), but gradually it morphed into a proper conference:
Festival Latinoamericano de Instalaci n de Software Libre (Latin
American Free Software Installation Festival)
 This FLISOL was hosted by the always great and always interesting
This FLISOL was hosted by the always great and always interesting
 It all started with the big bang! We nearly lost 33 of 36 disks on a
It all started with the big bang! We nearly lost 33 of 36 disks on a 
 Ten years ago, I
Ten years ago, I 
 Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Things got delayed a little recently as my main developer contact on the upstream side was on sick leave for a while. Fortunately, he has now fully recovered and work is getting back on track.
Recent Uploads to Debian related to Lomiri
Over the past 3 months I worked on the following bits and pieces regarding Lomiri in Debian:
Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Things got delayed a little recently as my main developer contact on the upstream side was on sick leave for a while. Fortunately, he has now fully recovered and work is getting back on track.
Recent Uploads to Debian related to Lomiri
Over the past 3 months I worked on the following bits and pieces regarding Lomiri in Debian:
 Over the course of the last year and a half, I ve been doing some self-directed
learning on how radios work. I ve gone from a very basic understanding of
wireless communications (there s usually some sort of antenna, I guess?) all
the way through the process of learning about and implementing a set of
libraries to modulate and demodulate data using my now formidable stash of SDRs.
I ve been implementing all of the RF processing code from first principals and
purely based on other primitives I ve written myself to prove to myself that I
understand each concept before moving on.
I figured that there was a fun capstone to be done here - the blind reverse
engineering and implementation of the protocol my cheep Amazon power switch
uses to turn on and off my Christmas Tree. All the work described in this post
was done over the course of a few hours thanks to help during the demodulation
from
Over the course of the last year and a half, I ve been doing some self-directed
learning on how radios work. I ve gone from a very basic understanding of
wireless communications (there s usually some sort of antenna, I guess?) all
the way through the process of learning about and implementing a set of
libraries to modulate and demodulate data using my now formidable stash of SDRs.
I ve been implementing all of the RF processing code from first principals and
purely based on other primitives I ve written myself to prove to myself that I
understand each concept before moving on.
I figured that there was a fun capstone to be done here - the blind reverse
engineering and implementation of the protocol my cheep Amazon power switch
uses to turn on and off my Christmas Tree. All the work described in this post
was done over the course of a few hours thanks to help during the demodulation
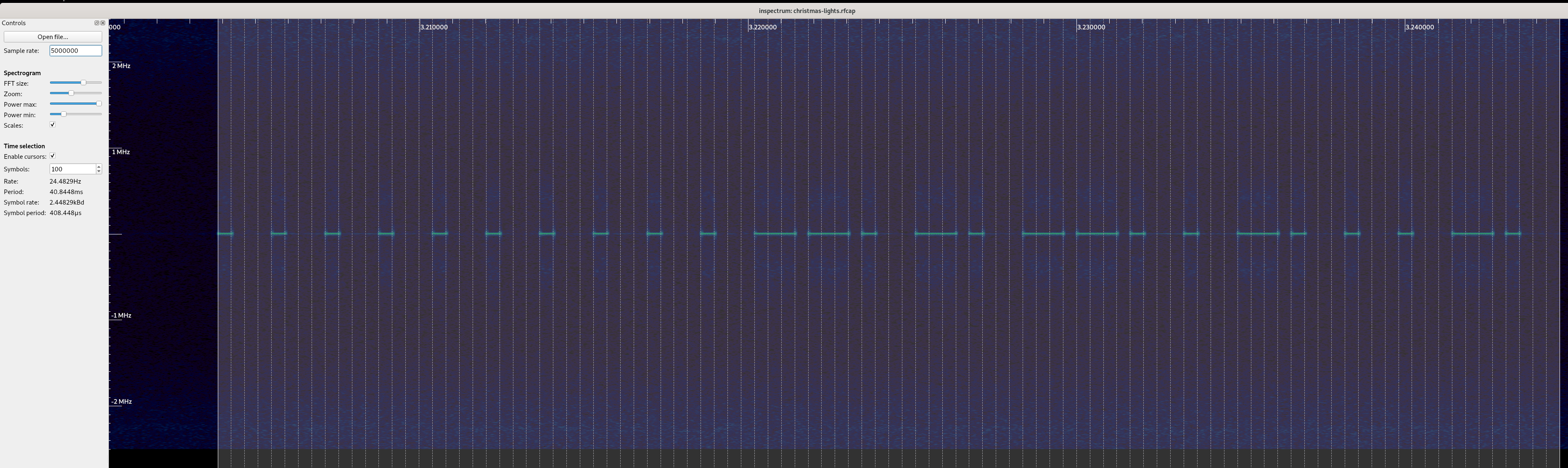
from  After taking a capture, I started to look at understanding what the modulation
type of the signal was, and how I may go about demodulating it.
Using
After taking a capture, I started to look at understanding what the modulation
type of the signal was, and how I may go about demodulating it.
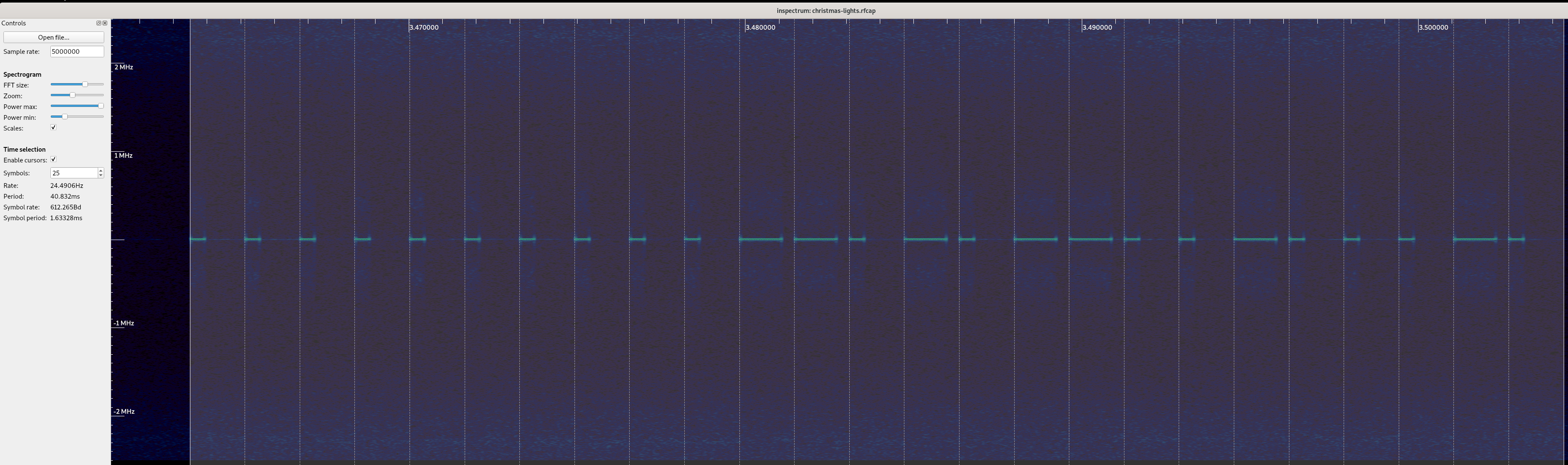
Using  Next, I started to measure the smallest pulse, and see if I could infer the
symbols per second, and try to decode it by hand. These types of signals are
generally pretty easy to decode by eye.
Next, I started to measure the smallest pulse, and see if I could infer the
symbols per second, and try to decode it by hand. These types of signals are
generally pretty easy to decode by eye.
 After some googling, I found a single lone
After some googling, I found a single lone
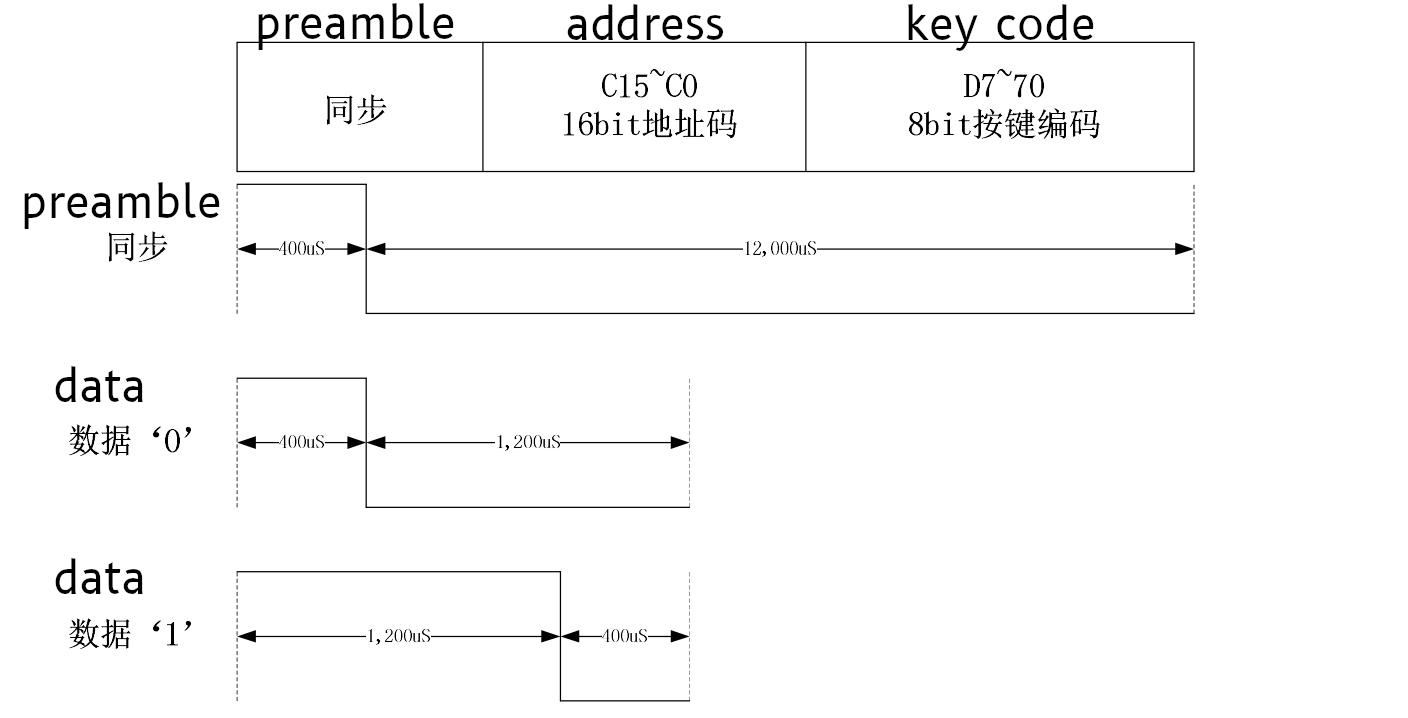 It s a bummer that we missed the clock sync / preamble pulse before the data
message, but that s OK somehow. It also turns out that 8 or 10 bit series of of
0"s wasn t clock sync at all - it was part of the address! Since it also turns
out that all devices made by this manufacturer have the hardcoded address of
It s a bummer that we missed the clock sync / preamble pulse before the data
message, but that s OK somehow. It also turns out that 8 or 10 bit series of of
0"s wasn t clock sync at all - it was part of the address! Since it also turns
out that all devices made by this manufacturer have the hardcoded address of
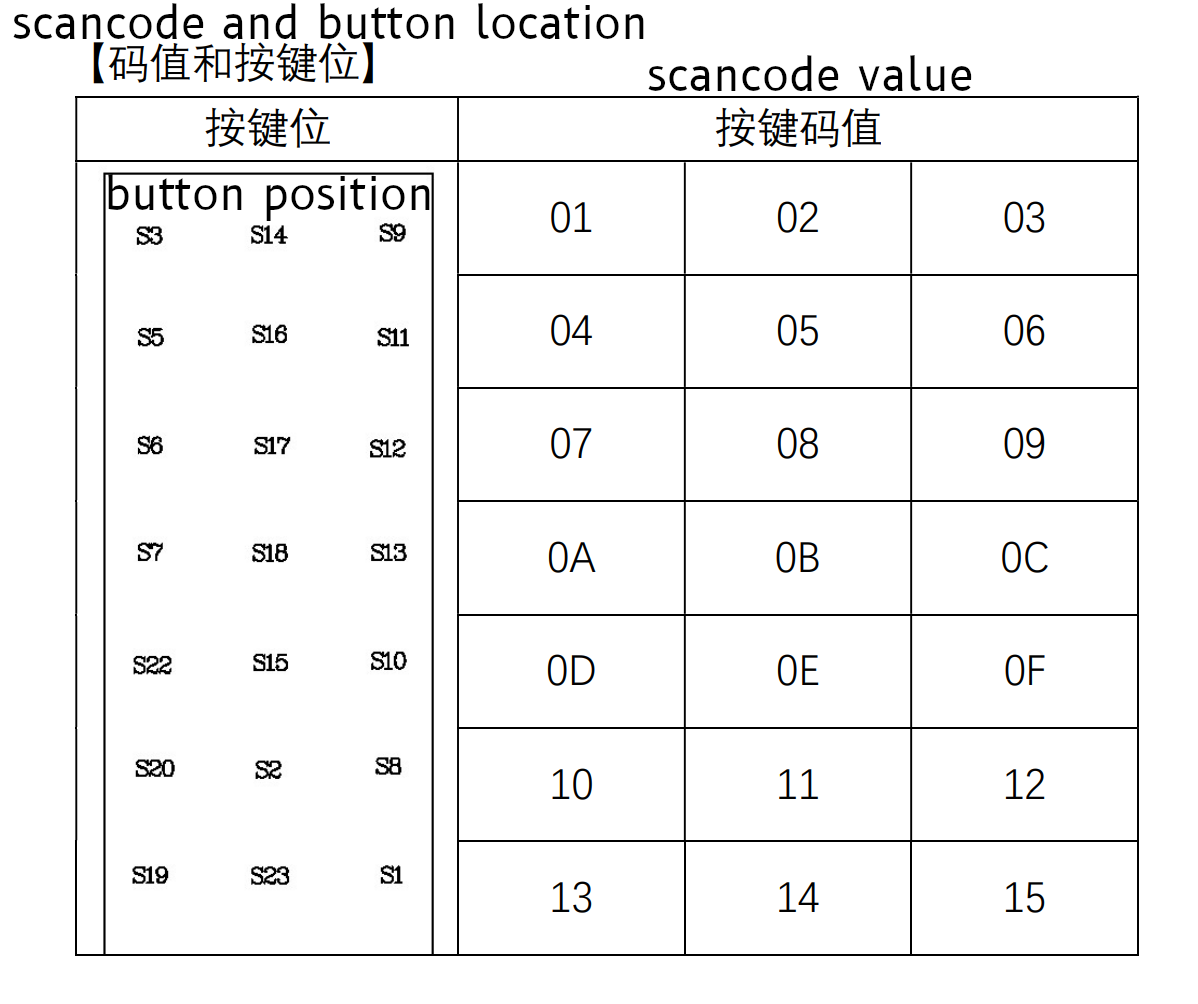 And even more interestingly, one of our scancodes ( Off , which is 0x94) shows up just
below this table, in the examples.
And even more interestingly, one of our scancodes ( Off , which is 0x94) shows up just
below this table, in the examples.
 Over all, I think this tells us we have the right bits to look at for
determining the scan code! Great news there!
Over all, I think this tells us we have the right bits to look at for
determining the scan code! Great news there!
 Despite having worked on a
Despite having worked on a  I managed to break a USB port on the Desk Pi. It has a pair of forward facing ports, I plugged my wireless keyboard dongle into it and when trying to remove it the solid spacer bit in the socket broke off. I ve never had this happen to me before and I ve been using USB devices for 20 years, so I m putting the blame on a shoddy socket.
The first drive I tried was an old Crucial M500 mSATA device. I have an adaptor that makes it look like a normal 2.5 drive so I used that. Unfortunately it resulted in a boot loop; the Pi would boot its initial firmware, try to talk to the drive and then reboot before even loading Linux. The DeskPi Pro comes with an m2 adaptor and I had a spare m2 drive, so I tried that and it all worked fine. This might just be power issues, but it was an unfortunate experience especially after the USB port had broken off.
(Given I ended up using an M.2 drive another case option would have been the
I managed to break a USB port on the Desk Pi. It has a pair of forward facing ports, I plugged my wireless keyboard dongle into it and when trying to remove it the solid spacer bit in the socket broke off. I ve never had this happen to me before and I ve been using USB devices for 20 years, so I m putting the blame on a shoddy socket.
The first drive I tried was an old Crucial M500 mSATA device. I have an adaptor that makes it look like a normal 2.5 drive so I used that. Unfortunately it resulted in a boot loop; the Pi would boot its initial firmware, try to talk to the drive and then reboot before even loading Linux. The DeskPi Pro comes with an m2 adaptor and I had a spare m2 drive, so I tried that and it all worked fine. This might just be power issues, but it was an unfortunate experience especially after the USB port had broken off.
(Given I ended up using an M.2 drive another case option would have been the  The case is a little snug; I was worried I was going to damage things as I slid it in. Additionally the construction process is a little involved. There s a good set of instructions, but there are a lot of pieces and screws involved. This includes a couple of
The case is a little snug; I was worried I was going to damage things as I slid it in. Additionally the construction process is a little involved. There s a good set of instructions, but there are a lot of pieces and screws involved. This includes a couple of  I hate the need for an external USB3 dongle to bridge from the Pi to the USB/SATA adaptor. All the cases I ve seen with an internal drive bay have to do this, because the USB3 isn t brought out internally by the Pi, but it just looks ugly to me. It s hidden at the back, but meh.
Fan control is via a USB/serial device, which is fine, but it attaches to the USB C power port which defaults to being a USB peripheral. Raspbian based kernels support device tree overlays which allows easy reconfiguration to host mode, but for a Debian based system I ended up rolling my own dtb file. I changed
I hate the need for an external USB3 dongle to bridge from the Pi to the USB/SATA adaptor. All the cases I ve seen with an internal drive bay have to do this, because the USB3 isn t brought out internally by the Pi, but it just looks ugly to me. It s hidden at the back, but meh.
Fan control is via a USB/serial device, which is fine, but it attaches to the USB C power port which defaults to being a USB peripheral. Raspbian based kernels support device tree overlays which allows easy reconfiguration to host mode, but for a Debian based system I ended up rolling my own dtb file. I changed


